
A classification of Quran translations using K-nearest neighbors, support vector machine and random forest method
DOI:
https://doi.org/10.59190/stc.v6i1.337Keywords:
Classifications, K-Nearest Neighbors, Quran Translation, Random Forest, Support Vector MachineAbstract
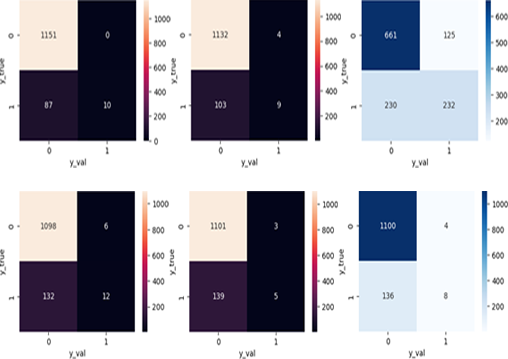
A Classification of Quranic verses based on topics is one of the efforts to facilitate understanding and searching for information in the holy book, especially for non-Arabic readers. This study aims to test and compare the performance of three text classification methods, namely K-nearest neighbors (KNN), support vector machine (SVM), and random forest (RF), in grouping translated Quranic verses into 15 topic classes, such as Islamic arkanul, faith, the Quran, science and its branches, charity, da'wah, jihad, human and social relations, and others. The dataset used is the English translation of the Quran with full preprocessing and an 80:20 data split for training and testing. The evaluation was carried out using accuracy, precision, recall, and F1-score metrics. The results show that RF achieved the best performance with an average F1-score of 58.48% and testing accuracy of 90.81%. KNN followed with an F1-score of 54.07% and the highest testing accuracy of 92.05%, while SVM produced the lowest F1-score at 50.76% and accuracy of 88.20%. The RF demonstrates a more balanced ability in recognizing all classes, KNN excels in overall accuracy, and SVM performs less optimally in this classification task. This research is expected to serve as a foundation for developing a more intelligent and contextual topic-based verse classification system.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Nur Delifah, Nazruddin Safaat Harahap, Surya Agustian, Muhammad Irsyad, Iwan Iskandar

This work is licensed under a Creative Commons Attribution 4.0 International License.








































