
Application of ensemble methods on transformer sequence classification of BERT base uncased and RoBERTa-base models for hate speech detection
DOI:
https://doi.org/10.59190/stc.v6i3.397Keywords:
BERT, Ensemble Learning, Hate Speech, RoBERTa, TransformerAbstract
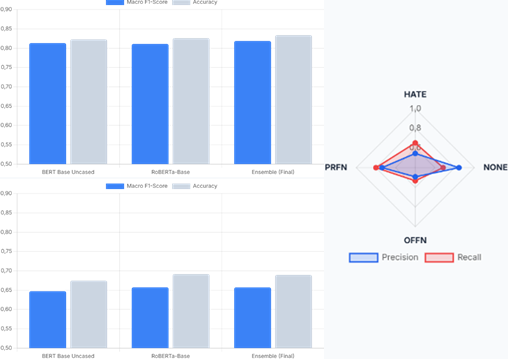
The rapid growth of social media platforms has brought a significant impact on the volume of digital interactions, which unfortunately is accompanied by a dramatic increase in the spread of hate speech and offensive language. Manual identification of negative content is highly inefficient and unscalable, thereby necessitating the development of state-of-the-art natural language processing (NLP) based automated detection systems. This study proposes the application of ensemble methods on Transformer architectures by combining two leading pre-trained language models, namely BERT (bidirectional encoder representations from transformers) base uncased and RoBERTa (robustly optimized BERT approach) base. The main focus of this research is to evaluate the performance of combining both models through a weighted average ensemble approach based on raw prediction probabilities (logits) with an even weighting ratio (50:50). Experiments were conducted using the public hate speech and offensive content identification (HASOC) 2021 dataset, covering two main scenarios: binary classification to distinguish NOT (normal) and HOF (hate/offensive) classes, and multi-class classification to categorize samples into HATE, OFFN (offensive), PRFN (profane), and NONE classes. To address the inherent challenge of significant class imbalance in the training data, this study implemented a custom class weighting function in the trainer module during the fine-tuning process. Empirical evaluation results demonstrate that the integration of the ensemble method effectively optimizes linguistic representation, suppresses prediction bias in minority classes, and improves performance stability. The ensemble model successfully achieved a macro F1-score of 0.8186 with 83.37% accuracy in the binary scenario, and a macro F1 score of 0.6570 with 68.93% accuracy in multi-class classification. This superior performance surpasses the capabilities of each baseline model individually, making it a robust hybrid architecture in tackling the variation of foul language in contemporary social media ecosystems.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Reza Mahendra Sardi, Surya Agustian, Rahmad Abdillah, Febi Yanto

This work is licensed under a Creative Commons Attribution 4.0 International License.








































