
Interpretative comparative analysis of LSTM and random forest for multi-label classification of English Qur’an translation
DOI:
https://doi.org/10.59190/stc.v6i3.373Keywords:
LSTM, Multi-Label Classification, Qur’an Translation, Random Forest, SMOTEAbstract
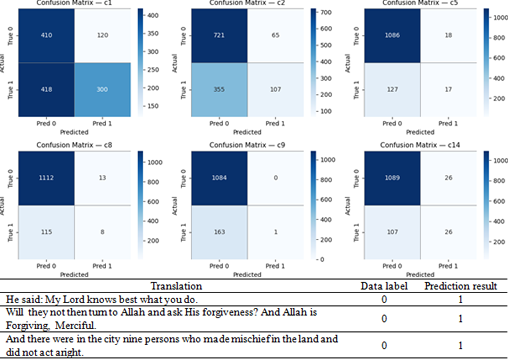
The rapid growth of digital Qur'anic resources has created a need for automated systems capable of accurately categorizing verses by thematic content. The thematic complexity of Qur'anic text, in which a single verse may simultaneously convey multiple moral, spiritual, and social messages, presents a significant challenge for automated classification systems. This study conducts a comparative and explainable evaluation of long short-term memory (LSTM) and random forest (RF) for multi-label classification of English Qur'an translations across six thematic categories: arkanul Islam, iman, amal, human and community relations, akhlak, and history and story. To address severe class imbalance, synthetic minority over-sampling technique (SMOTE) was applied per label, expanding the training set from 4,489 to 19,658 samples. LSTM captured sequential contextual relationships through integer token embeddings, while RF relied on TF-IDF vector representations. Evaluated on 1,248 unseen test verses, RF achieved a higher macro F1-score (0.2748) compared to LSTM (0.2432), while LSTM retained marginally higher accuracy (79.61% vs. 79.55%). Per-label analysis revealed that both models performed best on lexically explicit labels such as arkanul Islam and iman, but consistently failed on abstract categories such as akhlak, where LSTM recorded near-zero recall of 0.61% and RF only 6.10%. This study contributes empirical evidence that TF-IDF-based SMOTE interpolation is more effective for minority-class augmentation than token-sequence interpolation, and demonstrates that macro F1-score is a more appropriate evaluation metric than accuracy for imbalanced multi-label religious text classification.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Nur Delifah, Nazruddin Safaat Harahap, Okfalisa Okfalisa, Elvia Budianita

This work is licensed under a Creative Commons Attribution 4.0 International License.








































